Introduction to Database, components and structure of DBMS – logical structure – the 3 level architecture and mapping among them. Comparison between traditional file based system and DBMS. Advantages and drawbacks of DBMS
:
1. Introduction to Database
- A database is an organized collection of data that can be easily accessed, managed, and updated.
- It stores data efficiently and reduces redundancy.
2. Components of DBMS (Database Management System)
- Hardware: Physical devices like servers, storage, and client machines.
- Software: DBMS software (e.g., MySQL, Oracle).
- Data: Actual data stored in the database.
- Users:
- DBA (Database Administrator)
- Application programmers
- End-users
- Procedures: Instructions and rules for designing, using, and managing databases.
3. Structure of DBMS – Logical Structure
- The logical structure refers to how data is logically organized and perceived by users.
4. Three-Level Architecture (ANSI/SPARC Model)
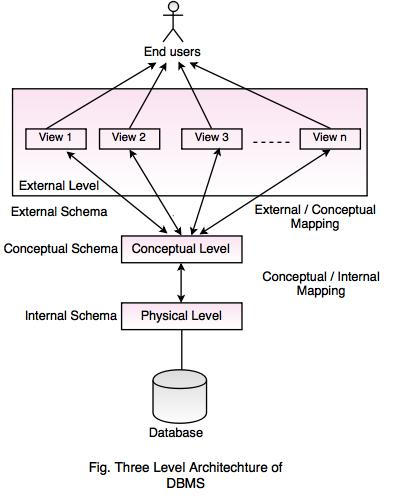
- External Level (View Level): User-specific views of the database.
- Conceptual Level (Logical Level): Overall logical structure (entities, relationships).
- Internal Level (Physical Level): Physical storage of data.
Mapping Among Levels:
- External to Conceptual Mapping: Ensures user views are consistent with the logical structure.
- Conceptual to Internal Mapping: Ensures the logical schema matches the physical storage.
5. Comparison: Traditional File-Based System vs DBMS

| Aspect | File-Based System | DBMS |
|---|---|---|
| Data Redundancy | High | Low |
| Data Consistency | Hard to maintain | Easy |
| Security | Minimal | Strong |
| Backup & Recovery | Manual | Automated |
| Data Access | Program-dependent | Query-based |
6. Advantages of DBMS
- Reduced data redundancy
- Data consistency
- Improved data security
- Backup and recovery
- Data sharing and multi-user access
- Data integrity
7. Drawbacks of DBMS
- High cost (hardware, software, training)
- Complex to set up and manage
- Performance can be slower for simple tasks
- Requires skilled personnel
Relational Model – What is relational model, Relational key constraints – candidate key, primary key, foreign key.ER Model – entities, attributes, relationship, and cardinality. Entity types, Entity sets Attributes and Keys Relationship types, Relationship Sets, converting ER diagram to relational tables. Database Schema
🔹 Relational Model
📌 What is the Relational Model?
- A Relational Model represents data in the form of tables (relations).
- Each table consists of rows (tuples) and columns (attributes).
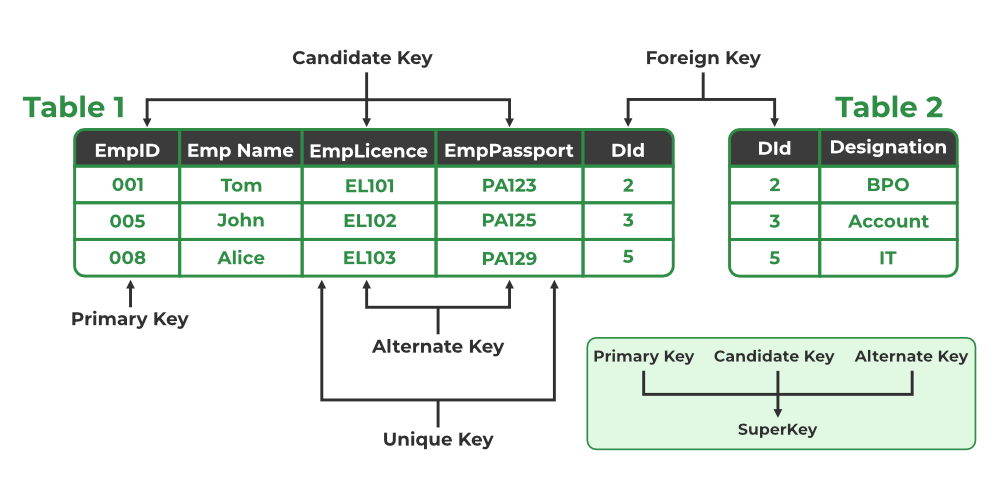
📌 Relational Key Constraints
- Candidate Key: A set of minimal attributes that uniquely identify a tuple.
- Primary Key: A selected candidate key that uniquely identifies each record.
- Foreign Key: An attribute in one table that refers to the primary key in another table, creating a relationship between tables.
🔹 ER Model (Entity-Relationship Model)
📌 Elements:
- Entity: Real-world object (e.g., Student, Employee)
- Attributes: Properties of entities (e.g., Student Name, Age)
- Relationship: Association between entities (e.g., Enrolled between Student and Course)
- Cardinality: Number of instances of one entity related to another (1:1, 1:N, N:M)
📌 Types:
- Entity Types: Strong (with key), Weak (without key)
- Entity Sets: Collection of similar entities
- Attributes and Keys: Simple, Composite, Derived, Multi-valued
- Relationship Types: One-to-one, One-to-many, Many-to-many
- Relationship Sets: Set of relationships of the same type
🔹 Converting ER Diagram to Relational Tables
Steps:
- Entity → Table
- Attributes → Columns
- Primary Key selection
- Relationships → Foreign Keys
- Handling Cardinality with appropriate foreign key placement
🔹 Database Schema
- Definition: A blueprint that defines the structure of the database (tables, relationships, constraints).
- Includes table definitions, data types, keys, and relationships.
Database Anomalies, CODD Rules and Normalization theory, 1 NF, 2 NF, 3NF and BCNF.
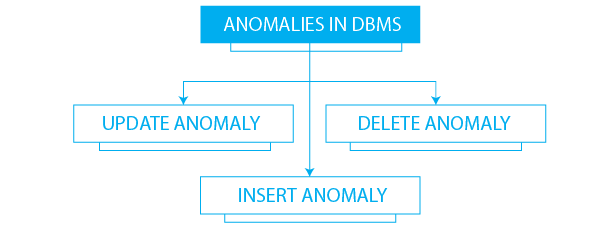
Database Anomalies
Here is an explanation of Database Anomalies in both Hindi and English:
1. Insertion Anomaly (Insertion Anomaly)
- English: An insertion anomaly occurs when it is difficult to insert new data into the database due to the design of the schema. For example, some data cannot be added without introducing inconsistencies or null values.
- Hindi: इनसर्शन एनोमली तब होती है जब स्कीमा के डिज़ाइन के कारण नए डेटा को डेटाबेस में डालना मुश्किल हो जाता है। उदाहरण के लिए, कुछ डेटा को जोड़े बिना असंगतता या नल मानों का परिचय होता है।
Example:
- English: If we have a table that stores employee details along with the department details, and we try to add a new department without adding an employee, the database will not allow it.
- Hindi: यदि हमारे पास एक तालिका है जो कर्मचारी विवरण और विभाग विवरण दोनों को संग्रहीत करती है, और हम एक नया विभाग जोड़ने की कोशिश करते हैं बिना किसी कर्मचारी को जोड़े, तो डेटाबेस इसे अनुमति नहीं देगा।
2. Update Anomaly (Update Anomaly)
- English: Update anomaly occurs when a change to data requires multiple updates to ensure consistency, and if all occurrences are not updated, it leads to data inconsistency.
- Hindi: अपडेट एनोमली तब होती है जब डेटा में परिवर्तन के लिए कई स्थानों पर अपडेट की आवश्यकता होती है, और यदि सभी स्थानों पर अपडेट नहीं किया जाता है, तो इससे डेटा में असंगति होती है।
Example:
- English: If the address of a company is stored in multiple places and we change the address, we must update all instances. If we miss updating one, the information will be inconsistent.
- Hindi: यदि एक कंपनी का पता कई स्थानों पर संग्रहित है और हम उस पते को बदलते हैं, तो हमें सभी स्थानों पर उसे अपडेट करना चाहिए। यदि हम एक को अपडेट करना भूल जाते हैं, तो जानकारी में असंगति होगी।
3. Deletion Anomaly (Deletion Anomaly)
- English: Deletion anomaly occurs when deleting data leads to the unintended loss of other important data stored in the same table.
- Hindi: डिलीशन एनोमली तब होती है जब डेटा को हटाने से उसी तालिका में संग्रहीत अन्य महत्वपूर्ण डेटा का अप्रत्याशित रूप से नुकसान होता है।
Example:
- English: If a table stores employee details and their department, deleting an employee’s record might inadvertently delete the department’s information, if that department is associated only with that employee.
- Hindi: यदि एक तालिका कर्मचारी विवरण और उनके विभाग को संग्रहीत करती है, तो किसी कर्मचारी का रिकॉर्ड हटाने से विभाग की जानकारी अप्रत्याशित रूप से हट सकती है, यदि वह विभाग केवल उसी कर्मचारी से संबंधित हो।
4. Redundancy Anomaly (Redundancy Anomaly)
- English: Redundancy anomaly occurs when there is unnecessary duplication of data due to improper design, leading to inconsistencies or inefficiencies.
- Hindi: रिडंडेंसी एनोमली तब होती है जब गलत डिज़ाइन के कारण डेटा की अनावश्यक पुनरावृत्ति होती है, जिससे असंगतता या अक्षमता हो सकती है।
Example:
- English: If an employee’s address is stored along with each order they place, the address data is repeated for every order, which is inefficient.
- Hindi: यदि एक कर्मचारी का पता उनके द्वारा किए गए प्रत्येक आदेश के साथ संग्रहीत होता है, तो पता डेटा प्रत्येक आदेश के लिए दोहराया जाता है, जो अप्रभावी है।
5. Normalization Issues (Normalization Problems)
- English: If the database is not normalized, anomalies like the ones mentioned above are more likely to occur. Normalization is the process of structuring data to reduce redundancy and maintain data integrity.
- Hindi: यदि डेटाबेस सामान्यीकृत (Normalization) नहीं है, तो ऊपर बताए गए प्रकार की एनोमली होने की संभावना अधिक होती है। सामान्यीकरण डेटा को संरचित करने की प्रक्रिया है जिससे पुनरावृत्ति को कम किया जाता है और डेटा की अखंडता बनाए रखी जाती है।
Example:
- English: A table that stores both employee and department data may face anomalies like insertion, update, and deletion issues if it is not properly normalized.
- Hindi: एक तालिका जो कर्मचारी और विभाग दोनों का डेटा संग्रहीत करती है, यदि वह ठीक से सामान्यीकृत नहीं है, तो उसे इनसर्शन, अपडेट और डिलीशन की समस्याएं हो सकती हैं।
Understanding these anomalies is crucial for effective database design. Proper normalization can help minimize these issues, ensuring data integrity and consistency across the database system.
Codd’s 12 Rules:
Here are Codd’s 12 Rules in both Hindi and English:
Codd’s 12 Rules for Relational Databases
1. Information Rule (Information Rule)
- English: All information in a relational database must be represented in one and only one way—by values in tables.
- Hindi: एक रिलेशनल डेटाबेस में सभी जानकारी को केवल एक ही तरीके से, यानी तालिकाओं में मानों के रूप में, प्रस्तुत किया जाना चाहिए।
2. Guaranteed Access Rule (Guaranteed Access Rule)
- English: Every data element (value) in a relational database is guaranteed to be accessible without ambiguity.
- Hindi: रिलेशनल डेटाबेस में हर डेटा तत्व (मान) को बिना किसी अस्पष्टता के उपलब्ध कराने की गारंटी दी जाती है।
3. Systematic Treatment of Null Values (Systematic Treatment of Null Values)
- English: Null values (i.e., missing or inapplicable information) must be systematically treated, not ambiguously.
- Hindi: नल मानों (यानी, गायब या अप्रासंगिक जानकारी) का व्यवस्थित तरीके से उपचार किया जाना चाहिए, न कि अस्पष्ट तरीके से।
4. Dynamic Online Catalog (Dynamic Online Catalog)
- English: The database should have a catalog that can be dynamically accessed and modified by authorized users, without needing to know the internal structure of the database.
- Hindi: डेटाबेस में एक कैटलॉग होना चाहिए जिसे प्राधिकृत उपयोगकर्ताओं द्वारा गतिशील रूप से एक्सेस और संशोधित किया जा सके, बिना डेटाबेस की आंतरिक संरचना को जाने।
5. Comprehensive Data Sublanguage Rule (Comprehensive Data Sublanguage Rule)
- English: A relational database must support at least one language that can express all queries, updates, and data definitions.
- Hindi: एक रिलेशनल डेटाबेस को कम से कम एक भाषा का समर्थन करना चाहिए जो सभी क्वेरी, अपडेट और डेटा परिभाषाओं को व्यक्त कर सके।
6. View Updating Rule (View Updating Rule)
- English: All views of the data must be updatable. If a user can view data, they should also be able to modify it.
- Hindi: डेटा के सभी दृश्य (views) को अपडेट किया जा सकता है। अगर उपयोगकर्ता डेटा को देख सकता है, तो उसे उसे संशोधित भी करना चाहिए।
7. High-Level Insert, Update, and Delete (High-Level Insert, Update, Delete)
- English: The database must support high-level operations for inserting, updating, and deleting data. These operations should not require low-level programming.
- Hindi: डेटाबेस को डेटा डालने, अपडेट करने और हटाने के लिए उच्च-स्तरीय ऑपरेशन का समर्थन करना चाहिए। इन ऑपरेशनों के लिए निम्न-स्तरीय प्रोग्रामिंग की आवश्यकता नहीं होनी चाहिए।
8. Physical Data Independence (Physical Data Independence)
- English: The application’s ability to access data should not be affected by changes in the physical storage of the data.
- Hindi: डेटा तक पहुँचने की एप्लिकेशन की क्षमता डेटा के भौतिक संग्रहण में होने वाले परिवर्तनों से प्रभावित नहीं होनी चाहिए।
9. Logical Data Independence (Logical Data Independence)
- English: The ability to change the logical schema without having to change the application’s ability to access data.
- Hindi: तार्किक स्कीमा को बदलने की क्षमता बिना एप्लिकेशन की डेटा तक पहुँचने की क्षमता को बदले।
10. Integrity Independence (Integrity Independence)
- English: Integrity constraints (rules that define the correctness of data) must be specified separately from the application programs.
- Hindi: सत्यता प्रतिबंधों (जो डेटा की सहीता को परिभाषित करते हैं) को एप्लिकेशन प्रोग्राम से अलग से परिभाषित किया जाना चाहिए।
11. Distribution Independence (Distribution Independence)
- English: The database should not be affected by where data is stored (whether in one place or distributed across multiple locations).
- Hindi: डेटाबेस को इस बात से प्रभावित नहीं होना चाहिए कि डेटा कहाँ संग्रहीत है (चाहे वह एक स्थान पर हो या विभिन्न स्थानों पर वितरित हो)।
12. Non-subversion Rule (Non-subversion Rule)
- English: If a relational system has a low-level (non-relational) interface, it must not be able to subvert or bypass the integrity of the database.
- Hindi: यदि एक रिलेशनल सिस्टम में निम्न-स्तरीय (गैर-रिलेशनल) इंटरफ़ेस है, तो उसे डेटाबेस की सत्यता को कमजोर करने या दरकिनार करने की अनुमति नहीं होनी चाहिए।
These 12 rules form the foundation for Codd’s theory on relational database systems and help ensure that databases function in a consistent, flexible, and efficient way.

ठीक है, अब मैं पूरा समझाव हिंदी में ही लिखता हूँ।
नॉर्मलाइजेशन सिद्धांत (Normalization Theory)
परिचय:
नॉर्मलाइजेशन एक प्रक्रिया है जिसमें डाटाबेस के डाटा को इस तरह व्यवस्थित किया जाता है कि:
- अतिरिक्तता (Redundancy) कम हो।
- सुसंगतता (Consistency) बनी रहे।
- अपडेट, इन्सर्ट, डिलीट करते समय त्रुटियाँ (Errors) न आएं।
सरल उदाहरण:
अगर एक ही छात्र का नाम और पता बार-बार तालिका में लिखा जा रहा है, तो हम उस जानकारी को अलग-अलग तालिकाओं में बाँट देंगे और उन्हें आपस में संबंध (Relation) के द्वारा जोड़ेंगे।
पहला सामान्य रूप (1NF – First Normal Form)
शर्तें:
- प्रत्येक कॉलम में अविभाज्य मान (Atomic Value) होना चाहिए – यानी किसी एक खाने (Cell) में एक से अधिक मान नहीं होने चाहिए।
- प्रत्येक पंक्ति (Row) अद्वितीय (Unique) होनी चाहिए।
उदाहरण (1NF से पहले):
| क्रमांक | नाम | विषय |
|---|---|---|
| 1 | अमित | गणित, भौतिकी |
| 2 | प्रिया | रसायन, जीवविज्ञान |
समस्या: विषय वाले कॉलम में एक से अधिक मान हैं।
1NF के बाद:
| क्रमांक | नाम | विषय |
|---|---|---|
| 1 | अमित | गणित |
| 1 | अमित | भौतिकी |
| 2 | प्रिया | रसायन |
| 2 | प्रिया | जीवविज्ञान |
दूसरा सामान्य रूप (2NF – Second Normal Form)
शर्तें:
- तालिका पहले से 1NF में हो।
- आंशिक निर्भरता (Partial Dependency) न हो।

अगर प्राथमिक कुंजी (Primary Key) संयुक्त (Composite) है, तो कोई भी गैर-कुंजी गुण (Non-Key Attribute) पूरी कुंजी पर निर्भर होना चाहिए, केवल उसके किसी हिस्से पर नहीं।
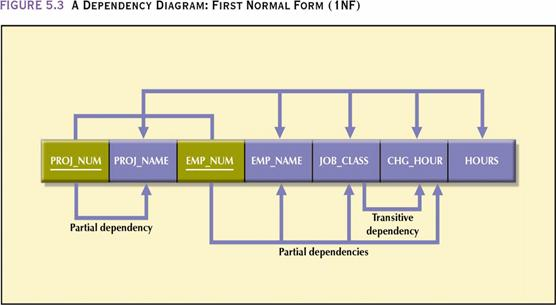
उदाहरण:
अगर तालिका की प्राथमिक कुंजी (क्रमांक, विषय) है और “नाम” केवल क्रमांक पर निर्भर करता है, तो यह आंशिक निर्भरता है।
समाधान: “नाम” को अलग तालिका में रख दें।
तीसरा सामान्य रूप (3NF – Third Normal Form)
शर्तें:
- तालिका 2NF में हो।
- परिवर्ती निर्भरता (Transitive Dependency) न हो।
- कोई गैर-कुंजी गुण (Non-Key Attribute) किसी अन्य गैर-कुंजी गुण पर निर्भर न हो।
उदाहरण:
अगर छात्र तालिका में:
- क्रमांक → नाम
- नाम → छात्रावास (Hostel)
तो यहाँ छात्रावास अप्रत्यक्ष रूप से क्रमांक पर निर्भर है (नाम के माध्यम से)।
समाधान: छात्रावास को अलग तालिका में रख दें।
बॉइस-कॉड सामान्य रूप (BCNF – Boyce-Codd Normal Form)
शर्तें:
- यह 3NF का एक सख्त रूप है।
- प्रत्येक Functional Dependency में बाईं ओर एक Super Key होनी चाहिए।
उदाहरण:
अगर तालिका में:
- पाठ्यक्रम (Course) → शिक्षक (Teacher)
- शिक्षक (Teacher) → पाठ्यक्रम (Course)
यहाँ कुछ Functional Dependency में Super Key का नियम टूट सकता है। इस स्थिति में तालिका को विभाजित कर BCNF बनाया जाता है।
संक्षिप्त सारांश:
- 1NF: डाटा को अविभाज्य बनाओ (एक कॉलम में एक ही मान)
- 2NF: आंशिक निर्भरता हटाओ
- 3NF: परिवर्ती निर्भरता हटाओ
- BCNF: प्रत्येक निर्भरता में बाईं ओर Super Key हो
Introduction to transaction and concept of concurrency control. Transaction and system concepts, desirable properties of transactions, transaction support in SQL. Concurrency control techniques, the locking protocol, serializable schedules, locks, 2 phase commit. Techniques, concurrency control based on
timestamp ordering
ट्रांजैक्शन का परिचय (Introduction to Transaction)
ट्रांजैक्शन डाटाबेस में एक कार्य की तार्किक इकाई (Logical Unit of Work) होती है, जो एक या अधिक ऑपरेशनों से मिलकर बनती है।
उदाहरण के लिए:
- बैंक खाते से पैसे ट्रांसफर करना (Debit + Credit)
- किसी ऑनलाइन शॉपिंग साइट पर ऑर्डर करना
महत्व:
ट्रांजैक्शन यह सुनिश्चित करता है कि या तो सभी ऑपरेशन सफलतापूर्वक पूरे हों, या कोई भी न हो (All or Nothing Principle)।
Concurrency Control की अवधारणा (Concept of Concurrency Control)
जब एक ही समय में कई ट्रांजैक्शन चल रही हों, तो उन्हें इस तरह नियंत्रित (Control) करना ज़रूरी है कि:
- डाटा में कोई गलत बदलाव न हो
- ट्रांजैक्शन का Isolation और Consistency बना रहे
उदाहरण:
मान लीजिए दो लोग एक ही बैंक खाते से एक साथ पैसे निकालने की कोशिश करें। अगर Concurrency Control न हो तो बैलेंस गलत हो सकता है।
System Concepts in Transactions
डाटाबेस सिस्टम में ट्रांजैक्शन को संभालने के लिए ये चीज़ें होती हैं:
- Transaction Manager – ट्रांजैक्शन को स्टार्ट, मैनेज और पूरा करता है।
- Concurrency Control Manager – एक साथ चल रही ट्रांजैक्शन को सुरक्षित रूप से चलाता है।
- Recovery Manager – अगर सिस्टम फेल हो जाए तो डाटा को वापस सही स्थिति में लाता है।
ट्रांजैक्शन के वांछनीय गुण (ACID Properties)
- Atomicity (परमाण्विकता) – ट्रांजैक्शन पूरी तरह हो या बिल्कुल न हो।
- Consistency (संगतता) – ट्रांजैक्शन के बाद डाटाबेस सही स्थिति में रहे।
- Isolation (अलगाव) – एक ट्रांजैक्शन का असर दूसरी पर न पड़े।
- Durability (स्थायित्व) – एक बार ट्रांजैक्शन Commit हो जाने के बाद उसका प्रभाव स्थायी हो।
SQL में Transaction Support
SQL में ट्रांजैक्शन को मैनेज करने के लिए कुछ कमांड्स:
BEGIN TRANSACTIONयाSTART TRANSACTION– ट्रांजैक्शन शुरू करनाCOMMIT– बदलाव स्थायी करनाROLLBACK– बदलाव रद्द करनाSAVEPOINT– ट्रांजैक्शन के बीच एक checkpoint बनाना
Concurrency Control Techniques (Concurrency Control की तकनीकें)
- Locking Protocol (लॉकिंग प्रोटोकॉल)
- किसी डाटा आइटम को Access करने से पहले लॉक करना।
- Shared Lock (S): केवल पढ़ने के लिए।
- Exclusive Lock (X): पढ़ने और लिखने दोनों के लिए।
- Serializable Schedules (क्रमबद्ध समयसूची)
- ट्रांजैक्शन इस तरह चलाई जाएँ कि उनका असर वैसा हो जैसे वे एक के बाद एक (serially) चलाई गई हों।
- Two-Phase Locking Protocol (2PL)
- Growing Phase: लॉक लेना, लेकिन रिलीज़ नहीं करना।
- Shrinking Phase: लॉक रिलीज़ करना, लेकिन नया लॉक न लेना।
- यह Deadlock का खतरा बढ़ा सकता है, लेकिन Serializability सुनिश्चित करता है।
2 Phase Commit Protocol (2PC)
डिस्ट्रिब्यूटेड सिस्टम में ट्रांजैक्शन Commit करने के लिए इस्तेमाल होता है।
- Phase 1 (Prepare Phase): Coordinator सभी पार्टिसिपेंट्स से पूछता है – तैयार हो?
- Phase 2 (Commit/Abort Phase): अगर सभी OK कहें तो Commit, वरना Rollback।
Timestamp Ordering Based Concurrency Control
हर ट्रांजैक्शन को शुरू होने पर एक Timestamp मिलता है।
- अगर कोई ट्रांजैक्शन किसी डाटा को पढ़ना या लिखना चाहती है, तो सिस्टम Timestamp चेक करता है।
- अगर नियम टूटता है (पुरानी ट्रांजैक्शन नई ट्रांजैक्शन के डाटा को ओवरराइट कर रही हो) तो पुरानी को Abort किया जा सकता है।